前言
本篇文章将介绍Java类和对象的相关内容。
关于面向对象
传统的结构化程序设计通过设计一系列的过程(即算法)来求解问题。一旦确定了这些过程,就要考虑存储数据的方式(即:算法 + 数据结构 = 程序)。注意在这种设计模式中,算法是第一位的,数据结构是第二位的。但是**面向对象程序设计(OOP)**调换了这一顺序:将数据放在第一位,然后再考虑操作数据的算法。
面向对象与面向过程的区别:
| 面向对象程序设计 | 面向过程程序设计(结构化编程) | |
|---|---|---|
| 定义 | 面向对象顾名思义就是把现实中的事务都抽象成为程序设计中的“对象”,其基本思想是一切皆对象,是一种“自下而上”的设计语言,先设计组件,再完成拼装。 | 面向过程是“自上而下”的设计语言,先定好框架,再增砖添瓦。通俗点,就是先定好main()函数,然后再逐步实现mian()函数中所要用到的其他方法。 |
| 特点 | 封装、继承、多态 | 算法 + 数据结构 |
| 优势 | 适用于大型复杂系统,方便复用 | 适用于简单系统,容易理解 |
| 劣势 | 比较抽象、性能比面向过程低 | 难以应对复杂系统,难以复用,不易维护、不易扩展 |
| 对比 | 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护 | 性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。 |
| 设计语言 | Java、Smalltalk、EIFFEL、C++、Objective-、C#、Python等 | C、Fortran |
面向对象的基本特征:
- 封装:保护内部的操作不被破坏;
- 继承:在原本的基础之上继续进行扩充;
- 多态:在一个指定的范围之内进行概念的转换。
类与对象的基本概念
把数据以及对数据的操作方法放在一起,作为一个相互依存的整体,这就是对象;对同类对象抽象出其共性,从而形成类。类与对象是整个面向对象中最基础的组成单元。
- 类:是抽象的概念集合,表示的是一个共性的产物,类之中定义的是属性和行为(方法);
- 对象:对象是一种个性的表示,表示一个独立的个体,每个对象拥有自己独立的属性,依靠属性来区分不同对象。
类与对象的定义和使用
定义标准类
定义一个标准类,通常拥有以下四个组成部分:
- 所有成员变量都要使用
private关键字修饰 - 为每一个成员变量编写一对
Getter/Setter方法 - 编写一个无参数的构造方法
- 编写一个全参数的构造方法
这样标准的类也叫做Java Bean,定义语法如下:
1 | class 类名称 { |
如下示例,定义一个Student类:
1 | public class Student { |
类的使用
类的定义完成之后,无法直接使用。如果要使用,首先需要导包(这不是必须的):
- 导包需要指出使用的类
- 对于和当前类属于同一个包的情况,可省略导包语句不写
java.lang包下的内容不需要导包- 导包格式:
import 包名称.类名称;(举例:import java.lang)
使用类必须依靠对象,实例化对象的方法有如下两种方式:
方式一:声明并实例化对象
1 | 类名称 对象名称 = new 类名称 () ; |
方式二:先声明对象,然后实例化对象
1 | 类名称 对象名称 = null ; |
示例,实例化一个student对象:
1 | //方式一 |
解释语句:实例化对象语句分为两个部分,new Student()构造了一个Student类型的对象,并且它的值是对新创建对象的引用。这个引用存储在变量student中。
引用数据类型与基本数据类型最大的不同在于:引用数据类型需要内存的分配和使用。所以,关键字new的主要功能就是分配内存空间,也就是说,只要使用引用数据类型,就要使用关键字new来分配内存空间。
实例化对象之后,可以按照如下方式进行类的操作:
- 调用类中的属性(变量):
对象名.成员变量名;(前提是类中的属性没有被关键字Private修饰) - 调用类中的方法:
对象名.成员方法名(参数);
示例:操作Student类
1 | public class Demo { |
输出结果:
1 | 姓名:张三,年龄:20 |
区分不同实例化的方式
从内存的角度分析。当然首先要给出两种内存空间的概念:
- 堆内存:保存对象的属性内容。堆内存需要用new关键字来分配空间;
- 栈内存:保存的是堆内存的地址(在这里为了分析方便,可以简单理解为栈内存保存的是对象的名字)。
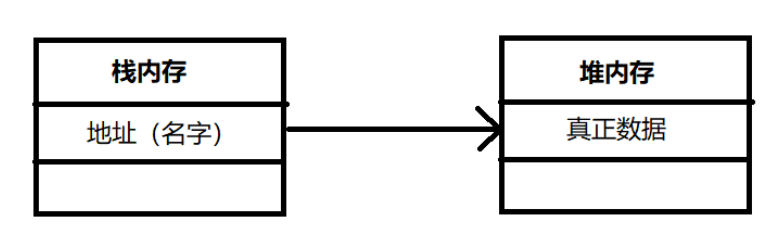
在任何情况下,只要看见关键字new,都表示要分配新的堆内存空间,一旦堆内存空间分配了,里面就会有类中定义的属性,并且属性内容都是其对应数据类型的默认值。
以上两种实例化对象方式内存表示如下:
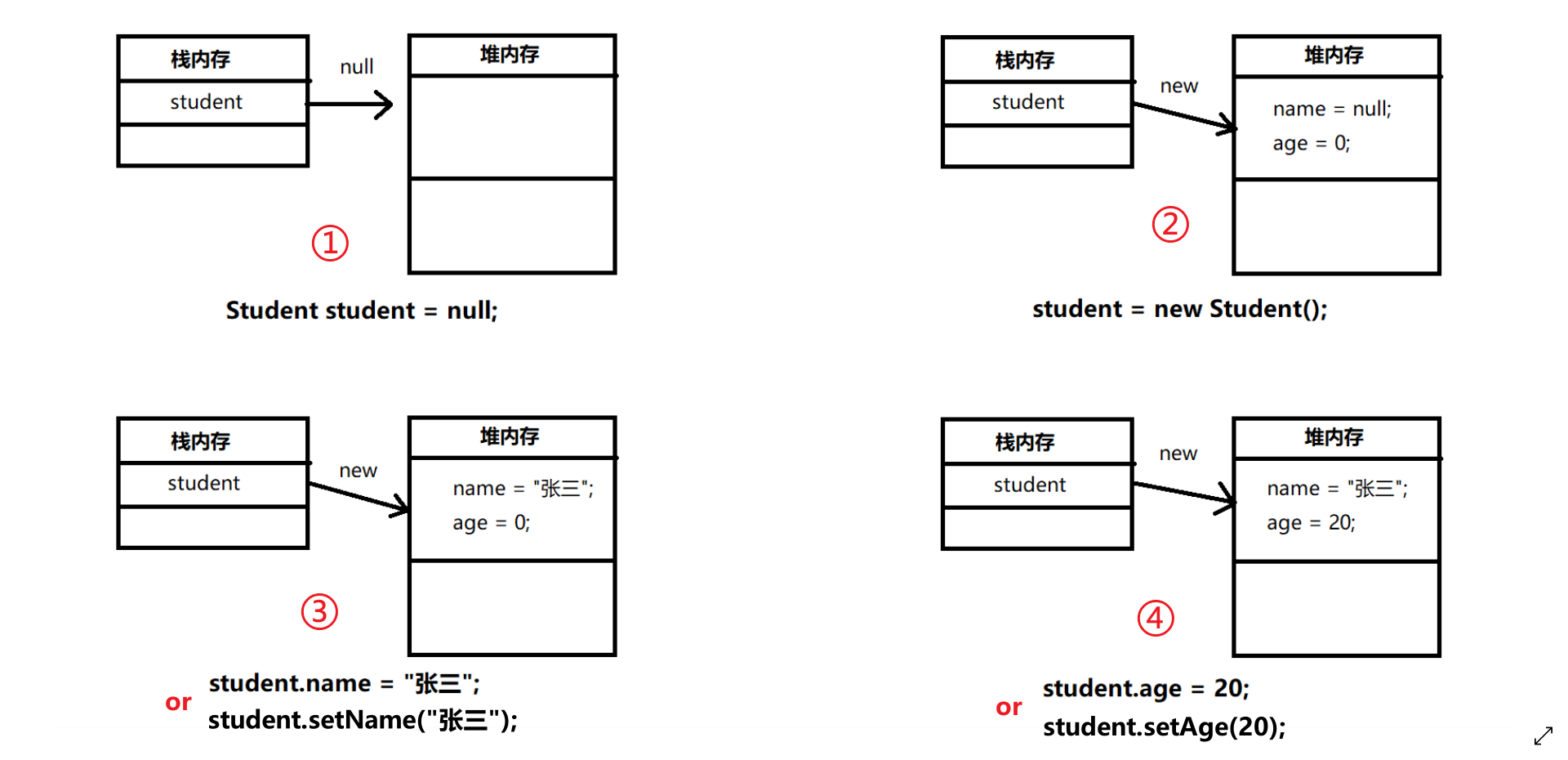
两种方式的差别在于①②,第一种声明并实例化的方式实际就是①②组合在一起,而第二种先声明然后实例化是把①和②分步骤来。
如果没有实例化对象的过程,直接使用类,如下(则会报错):
1 | public class Demo { |
运行结果:
1 | Exception in thread "main" java.lang.NullPointerException |
此时,程序只声明了Student对象,但并没有实例化Student对象(只有了栈内存,并没有对应的堆内存空间),则程序在编译的时候不会出现任何的错误,但是在执行的时候出现了上面的错误信息。这个错误信息表示的是“NullPointerException(空指向异常)”,这种异常只要是应用数据类型都有可能出现。
对象引用传递分析
同一块堆内存空间,可以同时被多个栈内存所指向,不同的栈可以修改同一块堆内存的内容。
引用传递代码示例:
1 | public class Demo { |
输出结果:
1 | 姓名:张三,年龄:20 |
对应的内存分配图如下:
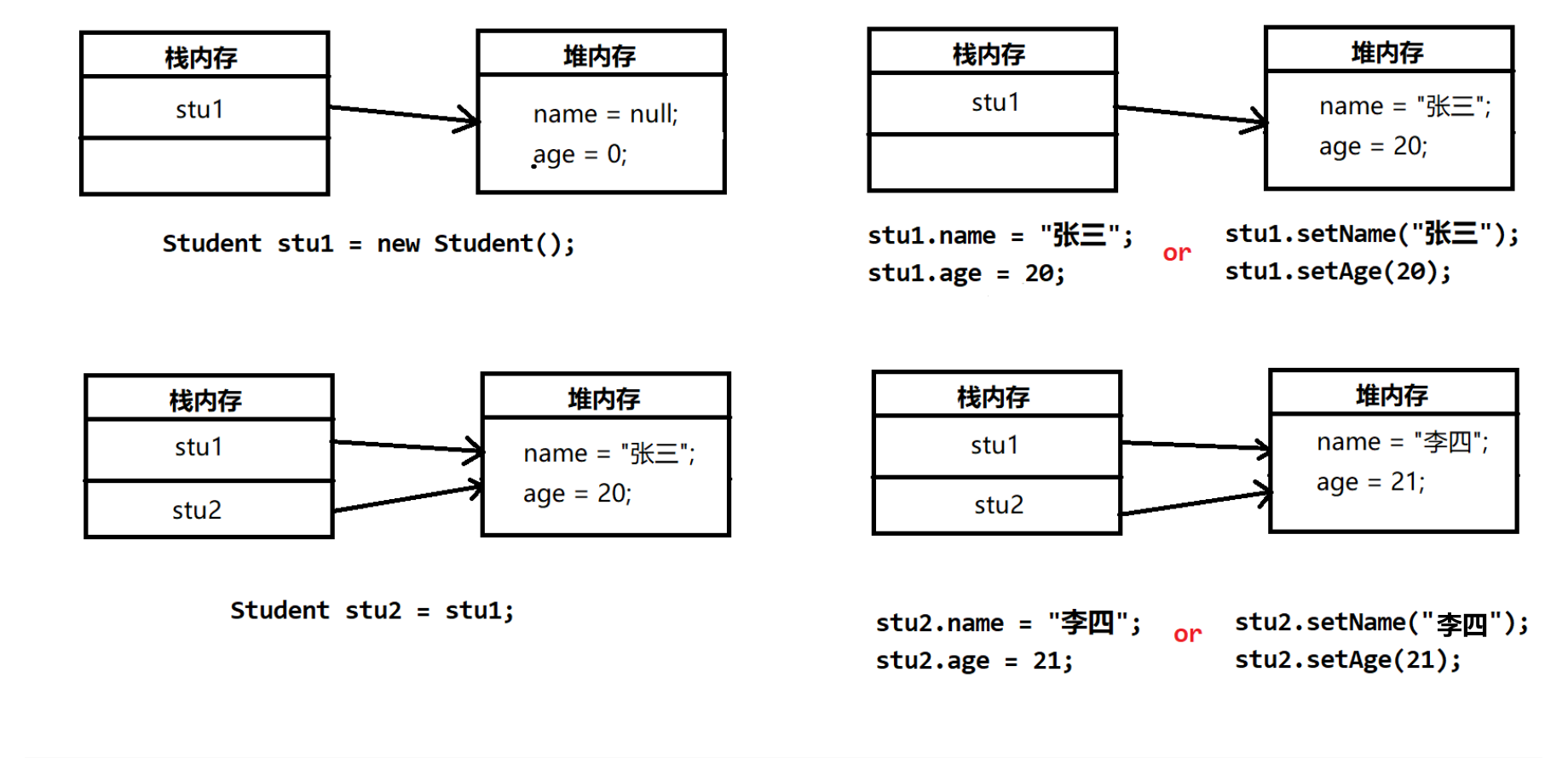
我们来看另一种情况:
1 | public class Demo { |
输出结果:
1 | 姓名:张三,年龄:20 |
对应的内存分配图如下:
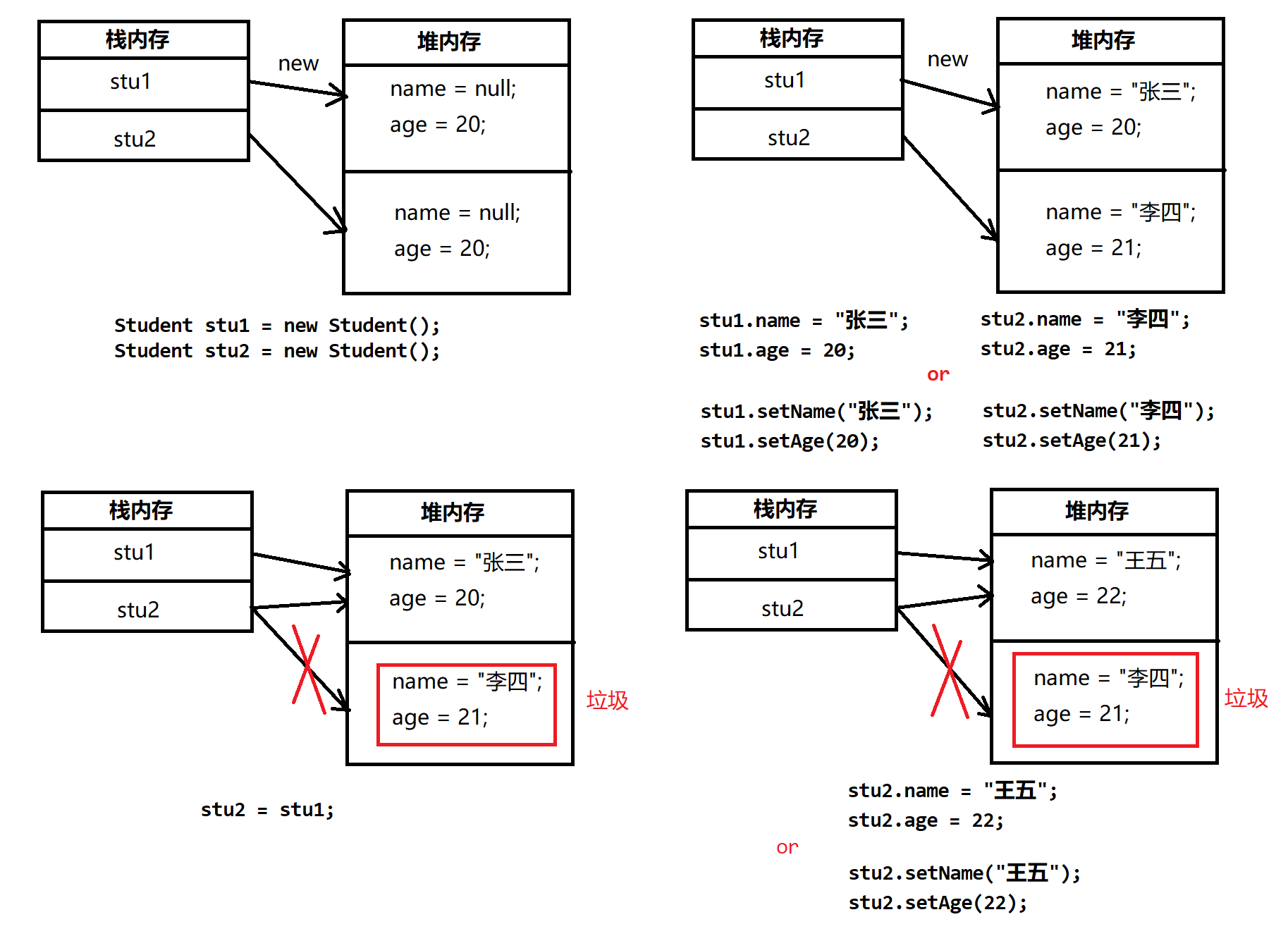
垃圾:指的是在程序开发之中没有任何对象所指向的一块堆内存空间,这块空间就成为垃圾,所有的垃圾将等待GC(垃圾收集器)不定期的进行回收与空间的释放。
关于封装性
前文提到面向对象的程序设计具有封装性。通俗的理解就是外部在调用类使用时,无法直接访问其内部属性,相当于对外不可见。举例如下代码:
1 | public class Demo { |
实际上在该段代码编写阶段就会直接提示错误信息,运行后可以也可以看到错误提示,name与age变量在Student类中是private访问控制。这就是封装性的具体体现,在Student类中,变量受到private关键字修饰,致使外部无法通过直接调用其属性并修改或访问。但是我们可以在定义类中增添对应属性的Setter/Getter方法来修改、访问。这就是具有封装性的标准类的一般创建方式。
关于构造方法
构造方法是在对象使用关键字new实例化的时候被调用。
构造方法与普通方法最大的区别在于:构造方法在实例化对象(new)的时候只调用一次,而普通方法是在实例化对象之后可以随意调用多次。
在创建类中会默认生成一个无参数的构造方法,但是一旦定义了一个构造方法,无参构造方法将不会自动生成。一个类中至少存在一个构造方法。
同样的,构造方法也属于方法,同样可以重载,一般在构建类的时候,会创建一个无参数的构造的方法以及一个全参数的构造方法。(如有需要,可以自行创建其他参数形式的构造方法):
1 | public class Student { |
在进行构造方法重载时有一个编写建议:所有重载的构造方法按照参数的个数由多到少,或者是由少到多排列。
关于匿名对象
没名字的对象称为匿名对象,对象的名字按照之前的内存关系来讲,在栈内存之中,而对象的具体内容在堆内存之中保存,这样,没有栈内存指向堆内存空间,就是一个匿名对象。
先定义一个Book类:
1 | public class Book { |
创建并使用匿名对象:
1 | public class Demo { |
输出结果:
1 | 书名:Java核心技术 卷Ⅰ,价格:149.0 |
匿名对象由于没有对应的栈内存指向,所以只能使用一次,一次之后就将成为垃圾,并且等待被GC回收释放。
结尾
参考资料:
《Java核心技术·卷 I Core Java Volume Ⅰ-Fundamentls(Eleven Edition)》






